
npm i koishi-plugin-nlp
# 或者
yarn add koishi-plugin-nlp# 自然语言处理 (NLP)
提示
本章介绍的功能由 koishi-plugin-nlp 插件提供。
koishi-plugin-nlp 提供了一种将自然语言转化成指令调用的方式。换句话说,就是从用户的任意消息中识别出意图,并交由对应的指令进行执行。用一张图表示它的工作原理就是这样:
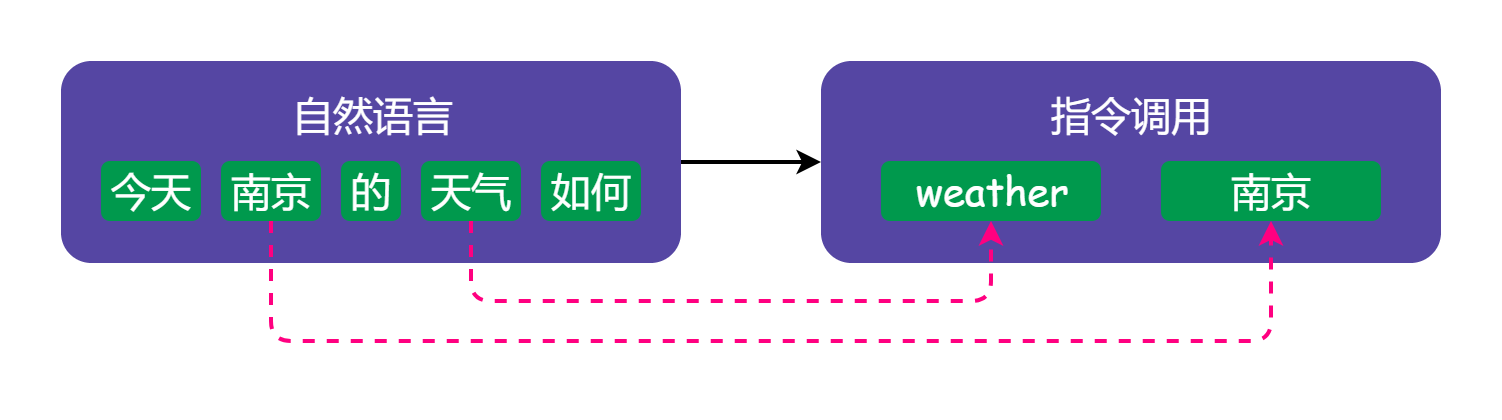
# 使用方法
首先安装插件:
提示
这个插件使用了著名的 结巴分词 的 NodeJS 绑定。如果安装失败可能是缺少一些运行环境导致的。
接着使用这个插件:
// 注册插件
ctx.plugin(require('koishi-plugin-nlp'))
// 假设我们写了这样一个指令
ctx.command('weather <location>', '查天气')
// 插件会在 Command 实例中添加一个 intend 方法
// 传入的第一个参数是要匹配的关键字
// 第二个参数是一个函数,当匹配到关键字时会执行
.intend('天气', (meta) => {
// 插件会在 meta.$parsed 对象中添加一个 tags 属性
// 这里的 ns 表示词性为地名
const tag = meta.$parsed.tags.find(({ tag }) => tag === 'ns')
// 返回一个置信度为 0.9 的结果
// 执行时的第一个参数取匹配到的词
if (tag) return { confidence: 0.9, args: [tag.word] }
})现在,向你的机器人发送“今天南京的天气如何”,机器人就会自动使用“南京”作为参数,调用 weather 这个指令了。
# 运作原理
现在让我们回顾一下上面的示例,来看看这个插件到底是如何工作的。
# cmd.intend()
首先,插件向 Command 示例添加了一个 intend() 方法,这个方法的作用是当检测到输入的句子中存在“天气”一词时进行匹配,预测出一个该指令的调用概率来。这个方法的回调函数返回一个对象,这个对象可以拥有下面的属性:
- args:
string[]由全部参数构成的数组 - options:
Record<string, any>由传入选项构成的键值对 - rest:
string额外参数的内容 - confidence:
number一个 0 到 1 之间的数,表示置信度
如果你对指令系统那一章还比较熟悉的话,就不难发现前三个参数也出现在了 ParsedCommandLine 对象 中。而最后一个参数表示的是置信度,置信度越高表示你越认为这句话表达了调用该指令的意图。而这又如何体现呢?很简单,如果一句输入同时触发了多个回调函数,则插件只会取返回的置信度最高的那个执行。
如果回调函数没有任何返回,或者返回了一个过低的置信度,则插件不会触发对应的指令。而在上面的例子中,如果 tag 存在,则返回了一个置信度为 0.9 的对象,否则不返回,这也表示只有当 tag 成功找到后插件才可能会调用查天气的指令。
# meta.$parsed.tags
同上面所说的 cmd.intend() 类似,meta.$parsed.tags 也是插件添加的属性。它表达了输入的句子的分词和词性信息。例如,当输入的句子是“今天南京的天气如何”时,meta.$parsed.tags 将会有下面的内容:
[ { word: '今天', tag: 't' }, // t (time) 时间词
{ word: '南京', tag: 'ns' }, // n (noun) 名词,ns (space) 地名
{ word: '的', tag: 'uj' }, // u (auxiliary) 助词,uj 助词的
{ word: '天气', tag: 'n' }, // n (noun) 名词
{ word: '如何', tag: 'r' } ] // r (pronoun) 代词这样一来,剩下的代码也就可以理解了:meta.$parsed.tags.find(({ tag }) => tag === 'ns') 的作用正是找出句子中的第一个地名并作为调用的参数。
# 配置项
# 设置最低置信度
上面已经介绍了如果返回的置信度过低则不会触发指令,那么这个边界在哪呢?对于 koishi-plugin-nlp 插件来说,默认的最低置信度为 0.5,但是你也可以手动修改这个边界值:
ctx.plugin(require('koishi-plugin-nlp'), {
// 重新设置最低置信度为 0.6
threshold: 0.6,
})# 手动设置词库
尽管 nodejieba 提供了内置词库,你仍然可以手动设置要使用的词库。以下是相关的配置项:
- dict:
string主词典,带权重和词性标签,建议使用默认词典 - hmmDict:
string隐式马尔科夫模型,建议使用默认词典 - userDict:
string用户词典,建议自己根据需要定制 - idfDict:
string关键词抽取所需的 idf 信息 - stopWordDict:
string关键词抽取所需的停用词列表
如果要设置自定义的词典,可以创建一个文本文件,将自定义的词汇一行一个地写入这个文件,然后将 userDict 选项设置为该文件的路径即可。